On some of our newer large-memory NFS servers, we are seeing servicesWas that 100G+ somewhat before any reclaiming of memory started,
killed with "failed to reclaim memory". According to our monitoring,
the server has >100G of physmem free at the time,
and the onlyThat swap is in use at all could be of interest. I wonder
solution seems to be rebooting. (There is a small amount of swap
configured and even less of it in use.)
Does this sound familiar toI'll note that you can delay the "failed to
anyone? What should we be monitoring that we evidently aren't now?
On Sep 9, 2025, at 12:20rC>PM, Garrett Wollman <wollman@bimajority.org> wrote:
N++On some of our newer large-memory NFS servers, we are seeing services killed with "failed to reclaim memory". According to our monitoring,
the server has >100G of physmem free at the time, and the only
solution seems to be rebooting. (There is a small amount of swap
configured and even less of it in use.) Does this sound familiar to
anyone? What should we be monitoring that we evidently aren't now?
-GAWollman
Garrett Wollman <wollman_at_bimajority.org> wrote on
Date: Tue, 09 Sep 2025 16:19:42 UTC :
On some of our newer large-memory NFS servers, we are seeing services
killed with "failed to reclaim memory". According to our monitoring,
the server has >100G of physmem free at the time,
Was that 100G+ somewhat before any reclaiming of memory started,
the lead-up to the notice?
Any likelihood of sudden, rapid, huge drops in free RAM based on
workload behavior?
Is NUMA involved?
and the only
solution seems to be rebooting. (There is a small amount of swap
configured and even less of it in use.)
That swap is in use at all could be of interest. I wonder
whaat it was doing when the swap was put to use or laundry
was growing that lead to swap being put to use.
what version of FreeBSD is this ?
<<On Wed, 10 Sep 2025 07:50:20 -0400, Mark Saad <nonesuch@longcount.org> said:I'm no ZFS guy, so I'm probably the last guy you should listen to,
what version of FreeBSD is this ?
Ah, yes, it's 14.3-RELEASE. It's an NFS server with three zpools
(boot plus two exported), total about 760 TiB.
-GAWollman
<<On Tue, 9 Sep 2025 12:19:21 -0700, Mark Millard <marklmi@yahoo.com> said:Bug or tuning weakness?
Garrett Wollman <wollman_at_bimajority.org> wrote on
Date: Tue, 09 Sep 2025 16:19:42 UTC :
On some of our newer large-memory NFS servers, we are seeing services
killed with "failed to reclaim memory". According to our monitoring,
the server has >100G of physmem free at the time,
Was that 100G+ somewhat before any reclaiming of memory started,
the lead-up to the notice?
That was within five minutes of munin-node getting shot by the OOM
killer. There was much less memory free ca. 24 hours before the
event.
Any likelihood of sudden, rapid, huge drops in free RAM based on
workload behavior?
I don't have access to client workloads, but it would have to be a bug
in ZFS if so; these are file servers, all they run is NFS.
I'd try tuning it via vfs.zfs.arc.sys_free?(The default is 0 and that says "use all of the memory" if I read it
Is NUMA involved?
Damn if I know.
and the only
solution seems to be rebooting. (There is a small amount of swap
configured and even less of it in use.)
That swap is in use at all could be of interest. I wonder
whaat it was doing when the swap was put to use or laundry
was growing that lead to swap being put to use.
It's pretty normal on these servers, which stay up for six months
between OS upgrades, for some userland daemons to get swapped out,
although I agree that it seems like it shouldn't happen given that the
size of memory (1 TiB) is much greater than the size of running
processes (< 1 GiB).
My suspicion here is that there's some sort of accounting error, but I
don't know where to look, and I only have data retrospectively, and
only the data that munin is collecting. (Someone else was on call
when this happened most recently and they reported that their login
shell kept on getting shot -- as was the getty on the serial console.)
-GAWollman
<<On Wed, 10 Sep 2025 07:50:20 -0400, Mark Saad <nonesuch@longcount.org> said:One simple thing you could do that might provide some insight
what version of FreeBSD is this ?
Ah, yes, it's 14.3-RELEASE. It's an NFS server with three zpools
(boot plus two exported), total about 760 TiB.
-GAWollman
One simple thing you could do that might provide some insight
into what is going on is..
- do "nfsstat -s" in a loop (once/sec) along with "date" written out
to some log file on the server.
- Then when the problem shows up, look at the log file and see what
RPCs/operations load the server was experiencing.
(read vs write vs lookup vs ???)
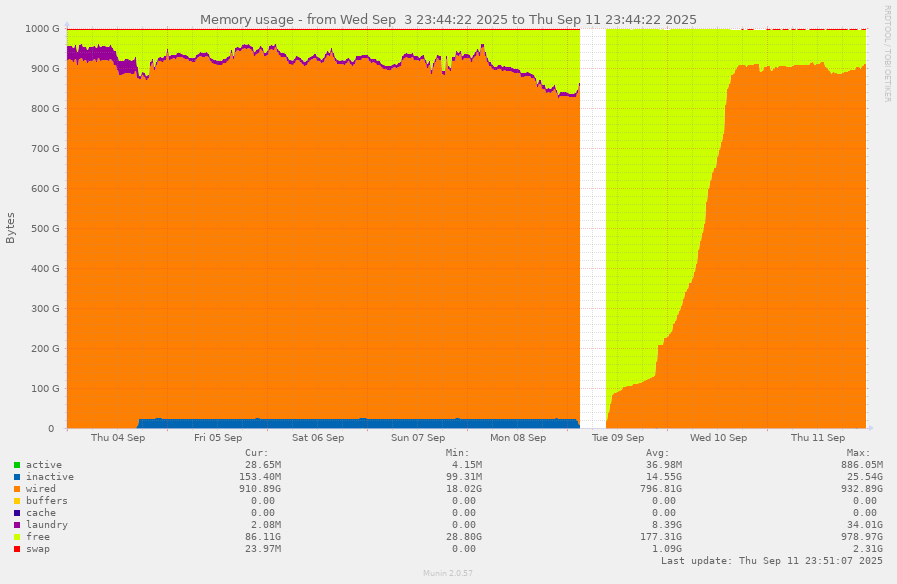
https://bimajority.org/%7Ewollman/memory-pinpoint%3D1756957462%2C1757648662.pngIs the growth to huge wired figures like 932.89G something
shows the memory utilization over the course of the past week
including the incident on Tuesday morning. I don't know why there's
25G of inactive pages for three days leading up to the OOM; perhaps
that's related? Inactive is normally much less than 1G.
https://bimajority.org/%7Ewollman/memory-pinpoint%3D1756957462%2C1757648662.png
shows the memory utilization over the course of the past week
including the incident on Tuesday morning. I don't know why there's
25G of inactive pages for three days leading up to the OOM; perhaps
that's related? Inactive is normally much less than 1G.
Is the growth to huge wired figures like 932.89G something
new --or has such been historically normal?
Garrett Wollman <wollman_at_bimajority.org>Given your report here: https://lists.freebsd.org/archives/freebsd-stable/2025-August/003024.html
Date: Fri, 12 Sep 2025 04:05:34 UTC
. . .
https://bimajority.org/%7Ewollman/memory-pinpoint%3D1756957462%2C1757648662.png
shows the memory utilization over the course of the past week
including the incident on Tuesday morning. I don't know why there's
25G of inactive pages for three days leading up to the OOM; perhaps
that's related? Inactive is normally much less than 1G.
Is the growth to huge wired figures like 932.89G something
new --or has such been historically normal?
===
Mark Millard
marklmi at yahoo.com
<<On Fri, 12 Sep 2025 08:23:34 -0700, Mark Millard <marklmi@yahoo.com> said:Ok, but don't we want something that prevents the arc from taking all
[I wrote:]
https://bimajority.org/%7Ewollman/memory-pinpoint%3D1756957462%2C1757648662.png
shows the memory utilization over the course of the past week
including the incident on Tuesday morning. I don't know why there's
25G of inactive pages for three days leading up to the OOM; perhaps
that's related? Inactive is normally much less than 1G.
Is the growth to huge wired figures like 932.89G something
new --or has such been historically normal?
Totally normal, that's the ARC warming up with client activity.
Typical machine learning datasets these days are on the order of a
terabyte, so they won't entirely fit in memory. (These systems also
have 2 TB of L2ARC but that gets discarded on reboot, so obviously
we'd like to avoid reboots.)
-GAWollman
Ok, but don't we want something that prevents the arc from taking all
the memory? (It seems like 932Gbytes should be close to a hard
upper bound for a system with 1Tbyte of ram?)
<<On Fri, 12 Sep 2025 08:50:10 -0700, Rick Macklem <rick.macklem@gmail.com> said:Maybe. A lot of things like he size of the buffer cache and buckets used
Ok, but don't we want something that prevents the arc from taking all
the memory? (It seems like 932Gbytes should be close to a hard
upper bound for a system with 1Tbyte of ram?)
Presently it says:
kstat.zfs.misc.arcstats.c_max: 1098065367040
That's 1 TiB less 1379 MiB. Which in all honesty *ought to be enough*
for munin-node, nrpe, ntpd, sendmail, inetd, lldpd, nslcd, sshd, syslogd, mountd, and nfsuserd.
-GAWollman
Garrett Wollman <wollman_at_bimajority.org>At various stages, what does:
Date: Fri, 12 Sep 2025 04:05:34 UTC
. . .
https://bimajority.org/%7Ewollman/memory-pinpoint%3D1756957462%2C1757648662.png
shows the memory utilization over the course of the past week
including the incident on Tuesday morning. I don't know why there's
25G of inactive pages for three days leading up to the OOM; perhaps
that's related? Inactive is normally much less than 1G.
Is the growth to huge wired figures like 932.89G something
new --or has such been historically normal?
<<On Fri, 12 Sep 2025 08:50:10 -0700, Rick Macklem <rick.macklem@gmail.com> said:If you look at arc_default_max() in sys/contrib/openzfs/module/os/freebsd/arc_os.c
Ok, but don't we want something that prevents the arc from taking all
the memory? (It seems like 932Gbytes should be close to a hard
upper bound for a system with 1Tbyte of ram?)
Presently it says:
kstat.zfs.misc.arcstats.c_max: 1098065367040
That's 1 TiB less 1379 MiB. Which in all honesty *ought to be enough*
for munin-node, nrpe, ntpd, sendmail, inetd, lldpd, nslcd, sshd, syslogd, mountd, and nfsuserd.
-GAWollman
On Fri, Sep 12, 2025 at 8:58rC>AM Garrett Wollman <wollman@bimajority.org> wrote:Here's another simple one..look at..
<<On Fri, 12 Sep 2025 08:50:10 -0700, Rick Macklem <rick.macklem@gmail.com> said:
Ok, but don't we want something that prevents the arc from taking all
the memory? (It seems like 932Gbytes should be close to a hard
upper bound for a system with 1Tbyte of ram?)
Presently it says:
kstat.zfs.misc.arcstats.c_max: 1098065367040
That's 1 TiB less 1379 MiB. Which in all honesty *ought to be enough*If you look at arc_default_max() in sys/contrib/openzfs/module/os/freebsd/arc_os.c
for munin-node, nrpe, ntpd, sendmail, inetd, lldpd, nslcd, sshd, syslogd, mountd, and nfsuserd.
you'll see it returns "allmem - 1Gbyte".
This may make sense for a machine with a few Gbytes of ram, but I'd bump it up for machines like you have. (As I noted, a system that boots with 128Gbyte->1Tbyte
of ram is going to size things a lot larger and "allmem" looks like
the total ram in the
system. They haven't even subtracted out what the kernel uses.)
(Disclaimer: I know nothing about ZFS, so the above may be crap!!)
It's a trivial function to patch, rick
-GAWollman
Lets see, 50% of memory allocated to mbufs and 99.9%
of physical memory allowed for the arc.
- This reminds me of the stats CNN puts up, where the
percentages never add up to 100.
<<On Fri, 12 Sep 2025 18:29:30 -0700, Rick Macklem <rick.macklem@gmail.com> said:I don't recall you mentioning your NIC speed, but 10Gbps->about 1Gbyte/sec. That's 100sec. But you certainly could be correct.
Lets see, 50% of memory allocated to mbufs and 99.9%
of physical memory allowed for the arc.
- This reminds me of the stats CNN puts up, where the
percentages never add up to 100.
The point being that the ARC is supposed to respond to backpressure
long before memory runs out. And again, we're talking about a system
with 100 GiB of outright FREE physical memory. There's no possible
way that can be fully allocated in less than 5 minutes -- the NICs
aren't that fast and the servers aren't doing anything else.
-GAWollman
On Fri, Sep 12, 2025 at 6:35rC>PM Garrett Wollman <wollman@bimajority.org> wrote:The problem is that it must react quickly and aggressively enough.
<<On Fri, 12 Sep 2025 18:29:30 -0700, Rick Macklem <rick.macklem@gmail.com> said:
Lets see, 50% of memory allocated to mbufs and 99.9%
of physical memory allowed for the arc.
- This reminds me of the stats CNN puts up, where the
percentages never add up to 100.
The point being that the ARC is supposed to respond to backpressure
long before memory runs out.
And again, we're talking about a systemI don't recall you mentioning your NIC speed, but 10Gbps->about 1Gbyte/sec. That's 100sec. But you certainly could be correct.
with 100 GiB of outright FREE physical memory. There's no possible
way that can be fully allocated in less than 5 minutes -- the NICs
aren't that fast and the servers aren't doing anything else.
rick
-GAWollman
The point being that the ARC is supposed to respond to backpressure
long before memory runs out. And again, we're talking about a system
with 100 GiB of outright FREE physical memory. There's no possible
way that can be fully allocated in less than 5 minutes -- the NICs
aren't that fast and the servers aren't doing anything else.
<<On Fri, 12 Sep 2025 21:35:26 -0400, Garrett Wollman <wollman@bimajority.org> said:
The point being that the ARC is supposed to respond to backpressure
long before memory runs out. And again, we're talking about a system
with 100 GiB of outright FREE physical memory. There's no possible
way that can be fully allocated in less than 5 minutes -- the NICs
aren't that fast and the servers aren't doing anything else.
The past couple of nights we've had failures of other NFS servers
(same FreeBSD build, different hardware, different clients, different
data). The most recent one, unlike the one I started this thread
with, didn't get so far as to invoke the OOM killer -- it seems to
have been stuck in arc_wait_for_eviction(). I wasn't in a position to
get a backtrace, so I can't tell if this was the call from arc_get_data_impl() (which is called for every block allocated but
normally just returns immediately) or the one from arc_lowmem() (which
is ultimately called from the vm_lowmem event handler when the system
is really out of memory).
As with previous failures, this one was with plenty of physical memory seemingly available (20 GiB out of 96 GiB). Separate swap partition,
of course, and after 34 minutes memory allocation is pretty much back
to where it was before the crash.
On Tue, Sep 16, 2025 at 09:33:26PM -0400, Garrett Wollman wrote:
As with previous failures, this one was with plenty of physical memory
seemingly available (20 GiB out of 96 GiB). Separate swap partition,
of course, and after 34 minutes memory allocation is pretty much back
to where it was before the crash.
Sorry to chime in late. Is this a NUMA system by any chance? That is,
what does sysctl vm.ndomains report?
It's hard to roll back my short-term memory to where it was a month
ago, but I checked several of our NFS servers of various vintages
(some old and small, some new) and all of them show vm.ndomains == 2.
| Sysop: | Amessyroom |
|---|---|
| Location: | Fayetteville, NC |
| Users: | 54 |
| Nodes: | 6 (0 / 6) |
| Uptime: | 19:48:02 |
| Calls: | 742 |
| Files: | 1,218 |
| D/L today: |
6 files (8,794K bytes) |
| Messages: | 184,914 |
| Posted today: | 1 |
{kind=link}
{kind=link}