| Sysop: | Amessyroom |
|---|---|
| Location: | Fayetteville, NC |
| Users: | 27 |
| Nodes: | 6 (0 / 6) |
| Uptime: | 38:00:35 |
| Calls: | 631 |
| Calls today: | 2 |
| Files: | 1,187 |
| D/L today: |
22 files (29,767K bytes) |
| Messages: | 173,681 |
Do any of you know of a reliable way to print a complete text copy of
the Windows 10 update list?
TIA
PS This stumped Copilot even.
Take back the tech companies from India & industry from China.
Do any of you know of a reliable way to print a complete text copy of
the Windows 10 update list?
TIA
PS This stumped Copilot even.
Do any of you know of a reliable way to print a complete text copy of
the Windows 10 update list?
Do any of you know of a reliable way to print a complete text copy of
the Windows 10 update list?
TIA
PS This stumped Copilot even.
John C. wrote:
Do any of you know of a reliable way to print a complete text copy ofOn your device or from the online Windows Update history web page?
the Windows 10 update list?
TIA
PS This stumped Copilot even.
"John C." <r9jmg0@yahoo.com> wrote:
Do any of you know of a reliable way to print a complete text copy of
the Windows 10 update list?
Run:
wmic qfe
or
wmic qfe list brief
in an admin cmd shell. The output is not sorted by date nor KB number.
You can redirect stdout into a file:
wmic qfe > c:\temp\KBlist.txt
When you view the file in, say, Notepad, you'll want to turn off line
wrap. Failed updates are not listed since obviously they didn't
install. Updates not using Component Based Servicing will not be listed
for the QFE (Quick Fix Engineering) class. To get those not in the QFE
list, use Powershell to query the WUA (Windows Update Agent) API, as mentioned in:
https://stackoverflow.com/questions/70762060/difference-between-wua-iupdatesearcher-and-wmic-qfe
which mentions to run in Powershell (all in one command line):
(New-Object -ComObject Microsoft.Update.Session).CreateUpdateSearcher().Search('IsInstalled=1').Updates | Format-Table -AutoSize
Someone elsewhere mentioned using Get-WUHistory in Powershell, but in
Win10 22H2 x64 I get back an error of no such cmdlet. However:
Get-HotFix
still works in Powershell. Looks like it is a cmdlet to run:
get-wmiobject -class win32_quickfixengineering
Then there is BelArc Advisor. It outputs an HTML page that displays in
your default web browser. At the bottom of the page, click on the "See
all installed hotfixes" hyperlink. Print (Ctrl+P) the new web page;
however, in the free version, a watermark gets added to the printout.
At a command prompt, you can run:
systeminfo.exe
which includes a list of hotfixes. Redirect stdout to a file if you
want to keep the output.
On Mon, 10/13/2025 8:25 AM, John C. wrote:
Do any of you know of a reliable way to print a complete text copy of
the Windows 10 update list?
TIA
PS This stumped Copilot even.
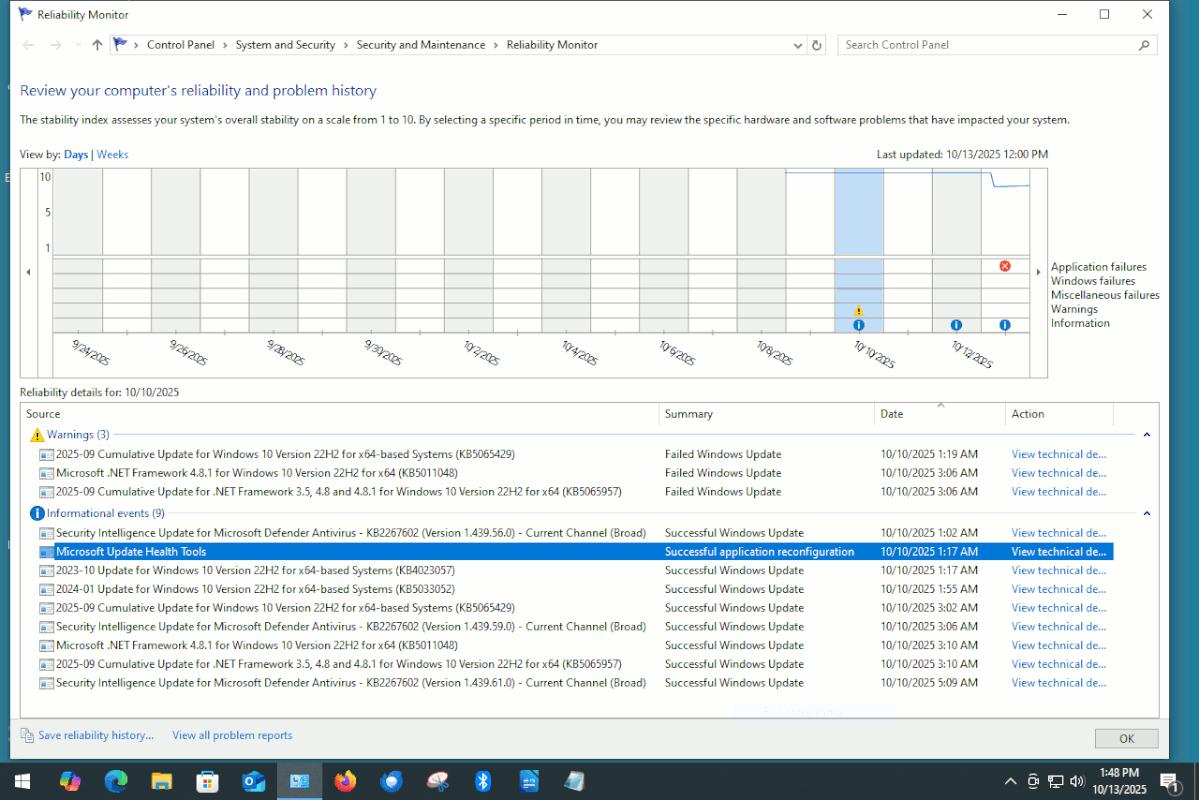
The Reliability Monitor seems to collect a good deal of info.
Ask CoPilot whether the Reliability Monitor data is available as text.
In this example, I did a Repair Install on this OS. I was
expecting, as a result, to see Windows Update activity happening
after doing this. And you can see some entries, as it patches up.
But this level of detail, is unlikely to be collected for
two years worth, and whatever "detail" log exists, would
have to be captured by you and stored each day, to not
lose that level of detail.
[Picture]
https://i.postimg.cc/7YHMTG9R/Example-Win10-Reliability-Monitor.gif
Paul
VanguardLH wrote:
"John C." <r9jmg0@yahoo.com> wrote:
Do any of you know of a reliable way to print a complete text copy of
the Windows 10 update list?
Run:
wmic qfe
or
wmic qfe list brief
in an admin cmd shell. The output is not sorted by date nor KB number.
You can redirect stdout into a file:
wmic qfe > c:\temp\KBlist.txt
When you view the file in, say, Notepad, you'll want to turn off line
wrap. Failed updates are not listed since obviously they didn't
install. Updates not using Component Based Servicing will not be listed
for the QFE (Quick Fix Engineering) class. To get those not in the QFE
list, use Powershell to query the WUA (Windows Update Agent) API, as
mentioned in:
https://stackoverflow.com/questions/70762060/difference-between-wua-iupdatesearcher-and-wmic-qfe
which mentions to run in Powershell (all in one command line):
(New-Object -ComObject Microsoft.Update.Session).CreateUpdateSearcher().Search('IsInstalled=1').Updates | Format-Table -AutoSize
Someone elsewhere mentioned using Get-WUHistory in Powershell, but in
Win10 22H2 x64 I get back an error of no such cmdlet. However:
Get-HotFix
still works in Powershell. Looks like it is a cmdlet to run:
get-wmiobject -class win32_quickfixengineering
Then there is BelArc Advisor. It outputs an HTML page that displays in
your default web browser. At the bottom of the page, click on the "See
all installed hotfixes" hyperlink. Print (Ctrl+P) the new web page;
however, in the free version, a watermark gets added to the printout.
At a command prompt, you can run:
systeminfo.exe
which includes a list of hotfixes. Redirect stdout to a file if you
want to keep the output.
Thanks very much for your (as usual) well thought out reply, VanguardLH.
I'll take a look at all that.
In the mean time, I was able to more or less accomplish what I wanted by doing screenshots of the list, then running those images through Google Keep's OCR engine.
It's an online service, of course, but IME it's a very accurate way to
OCR images and did a reasonably good job for me here.
On 25/10/14 05:11 AM, John C. wrote:
VanguardLH wrote:
"John C." <r9jmg0@yahoo.com> wrote:
Do any of you know of a reliable way to print a complete text copy of
the Windows 10 update list?
Run:
wmic qfe
or
wmic qfe list brief
in an admin cmd shell. The output is not sorted by date nor KB number.
You can redirect stdout into a file:
wmic qfe > c:\temp\KBlist.txt
When you view the file in, say, Notepad, you'll want to turn off line
wrap. Failed updates are not listed since obviously they didn't
install. Updates not using Component Based Servicing will not be listed >>> for the QFE (Quick Fix Engineering) class. To get those not in the QFE
list, use Powershell to query the WUA (Windows Update Agent) API, as
mentioned in:
https://stackoverflow.com/questions/70762060/difference-between-wua-iupdatesearcher-and-wmic-qfe
which mentions to run in Powershell (all in one command line):
(New-Object -ComObject Microsoft.Update.Session).CreateUpdateSearcher().Search('IsInstalled=1').Updates | Format-Table -AutoSize
Someone elsewhere mentioned using Get-WUHistory in Powershell, but in
Win10 22H2 x64 I get back an error of no such cmdlet. However:
Get-HotFix
still works in Powershell. Looks like it is a cmdlet to run:
get-wmiobject -class win32_quickfixengineering
Then there is BelArc Advisor. It outputs an HTML page that displays in
your default web browser. At the bottom of the page, click on the "See
all installed hotfixes" hyperlink. Print (Ctrl+P) the new web page;
however, in the free version, a watermark gets added to the printout.
At a command prompt, you can run:
systeminfo.exe
which includes a list of hotfixes. Redirect stdout to a file if you
want to keep the output.
Thanks very much for your (as usual) well thought out reply, VanguardLH.
I'll take a look at all that.
In the mean time, I was able to more or less accomplish what I wanted by
doing screenshots of the list, then running those images through Google
Keep's OCR engine.
It's an online service, of course, but IME it's a very accurate way to
OCR images and did a reasonably good job for me here.
What I'm looking for is a way to print a list of everything shown here:
Settings
Update & Security
View update history
including:
Quality Updates (I have 19 of them)
Driver Updates (there are 6 of them)
Definition Updates (there are 50 of them)
Other Updates (there are 6 of them)
Of course, clicking on the angle bracket next to each category converts
it to a down arrowhead and drops down the list of each category. With
all of the categories dropped down, the history shows a complete list of
all updates for my computer. That is what I wanted to be able to save a
text version of, but the update history at that location doesn't allow
for that.
John C. wrote:
John C. wrote:
VanguardLH wrote:
"John C." <r9jmg0@yahoo.com> wrote:
Do any of you know of a reliable way to print a complete text copy
of the Windows 10 update list?
Run:
wmic qfe
or
wmic qfe list brief
...
In the mean time, I was able to more or less accomplish what I
wanted by doing screenshots of the list, then running those images
through Google Keep's OCR engine.
What I'm looking for is a way to print a list of everything shown
here:
Settings
Update & Security
View update history
The easy way is to download this Nirsoft viewer: https://www.nirsoft.net/utils/windows_updates_history_viewer.html
Thanks very much for your (as usual) well thought out reply, VanguardLH.(As someone else has pointed out - and VLH has agreed, having forgotten
I'll take a look at all that.
In the mean time, I was able to more or less accomplish what I wanted by doing screenshots of the list, then running those images through Google> Keep's OCR engine.
It's an online service, of course, but IME it's a very accurate way to
OCR images and did a reasonably good job for me here.
On 2025/10/14 13:11:26, John C. wrote:[]
doing screenshots of the list, then running those images through GoogleRecently I've used IrfanView's OCR function (under F9) to OCR
Keep's OCR engine.
It's an online service, of course, but IME it's a very accurate way to>> OCR images and did a reasonably good job for me here.
screenshots (and anything else - even record labels from YouTube!); it
seems to work pretty well (certainly fine on screenshots), and of course _isn't_ online.
(I think it's a plugin, but I always download the plugins whenever I get
a new version of IrfanView - they're on th same page, https://www.irfanview.com/ [bottom of home page].)
On 2025/10/14 13:11:26, John C. wrote:
[]
Thanks very much for your (as usual) well thought out reply, VanguardLH.
I'll take a look at all that.
(As someone else has pointed out - and VLH has agreed, having forgotten
about it - there's a NirSoft utility that can do what John C. wanted. I
have no experience of that particular one, but I agree NirSoft utilities normally do what they're supposed to, and do it well.)
Recently I've used IrfanView's OCR function (under F9) to OCR
In the mean time, I was able to more or less accomplish what I wanted by
doing screenshots of the list, then running those images through Google
Keep's OCR engine.
It's an online service, of course, but IME it's a very accurate way to
OCR images and did a reasonably good job for me here.
screenshots (and anything else - even record labels from YouTube!); it
seems to work pretty well (certainly fine on screenshots), and of course _isn't_ online.
(I think it's a plugin, but I always download the plugins whenever I get
a new version of IrfanView - they're on th same page, https://www.irfanview.com/ [bottom of home page].)
Take back the techGoogle is investing $15 billion in India. This was announced by Sundar
companies from India & industry from China.
On 10/14/2025 7:38 PM, J. P. Gilliver wrote:
On 2025/10/14 13:11:26, John C. wrote:
[]
Thanks very much for your (as usual) well thought out reply, VanguardLH. >>> I'll take a look at all that.
(As someone else has pointed out - and VLH has agreed, having forgotten
about it - there's a NirSoft utility that can do what John C. wanted. I
have no experience of that particular one, but I agree NirSoft utilities
normally do what they're supposed to, and do it well.)
Recently I've used IrfanView's OCR function (under F9) to OCR
In the mean time, I was able to more or less accomplish what I wanted by >>> doing screenshots of the list, then running those images through Google
Keep's OCR engine.
It's an online service, of course, but IME it's a very accurate way to
OCR images and did a reasonably good job for me here.
screenshots (and anything else - even record labels from YouTube!); it
seems to work pretty well (certainly fine on screenshots), and of course
_isn't_ online.
(I think it's a plugin, but I always download the plugins whenever I get
a new version of IrfanView - they're on th same page,
https://www.irfanview.com/ [bottom of home page].)
Even if you can get it as an image PDF file, you can still use Irfanview to OCR it.-a-a There are two ways.-a On you can use the camera function of Adobe Reader to cut the section you want to OCR, paste it into Irfanview, and then run the OCR on it.
The second way is to load the PDF file directly into Irfanveiw and running the OCR on it.
I have used both the Tesseract OCR (64bit) plugin and the OCR_KADMOS (32bit) plugins.-a Both do a great job of converting an image to text. One note: To get the best OCR, you sometimes have to zoom in on the text in question to get it as big as possible.
John C. wrote:
The easy way is to download this Nirsoft viewer: https://www.nirsoft.net/utils/windows_updates_history_viewer.html
(snip)
What I'm looking for is a way to print a list of everything shown here:
Settings
-a-a Update & Security
-a-a-a-a View update history
including:
-a-a Quality Updates (I have 19 of them)
-a-a Driver Updates (there are 6 of them)
-a-a Definition Updates (there are 50 of them)
-a-a Other Updates (there are 6 of them)
Of course, clicking on the angle bracket next to each category converts
it to a down arrowhead and drops down the list of each category. With
all of the categories dropped down, the history shows a complete list of
all updates for my computer. That is what I wanted to be able to save a
text version of, but the update history at that location doesn't allow
for that.
It needs no install, shows everything including failed updates, and will generate a HTML report of all or selected entries.
Recently I've used IrfanView's OCR function (under F9) to OCR
screenshots (and anything else - even record labels from YouTube!); it
seems to work pretty well (certainly fine on screenshots), and of course _isn't_ online.
(I think it's a plugin, but I always download the plugins whenever I get
a new version of IrfanView - they're on th same page, https://www.irfanview.com/ [bottom of home page].)
J. P. Gilliver <G6JPG@255soft.uk> wrote:There are different meanings of space required. One is the space on
[...]
Recently I've used IrfanView's OCR function (under F9) to OCR
screenshots (and anything else - even record labels from YouTube!); it
seems to work pretty well (certainly fine on screenshots), and of course
_isn't_ online.
(I think it's a plugin, but I always download the plugins whenever I get
a new version of IrfanView - they're on th same page,
https://www.irfanview.com/ [bottom of home page].)
Thanks for that tip. Can you check (Help -> Installed Plugins...)
*which* plugin you use, the OCR.Dll one ('OCR using Tesseract OCR') or
the OCR_KADMOS one (<https://www.irfanview.info/plugins/kadmos/>?
I tried the OCR_KADMOS one (in old 4.60 IrfanView 32-bit), but that
did not seem too work too well.
I have now updated to version 4.72 and am installing 'Tesseract', but
that seems a bit overwhelming (which components (not) to install?
"Space required 255.4MB"! (isn't IrfanView supposed to be
lean-and-mean?), etc.)
On 10/15/2025 10:33 AM, Frank Slootweg wrote:I've never used that function before! It lists a lot of plugins, about
J. P. Gilliver <G6JPG@255soft.uk> wrote:
[...]
Recently I've used IrfanView's OCR function (under F9) to OCR
screenshots (and anything else - even record labels from YouTube!); it
seems to work pretty well (certainly fine on screenshots), and of course >>> _isn't_ online.
(I think it's a plugin, but I always download the plugins whenever I get >>> a new version of IrfanView - they're on th same page,
https://www.irfanview.com/ [bottom of home page].)
Thanks for that tip. Can you check (Help -> Installed Plugins...)
*which* plugin you use, the OCR.Dll one ('OCR using Tesseract OCR') or>> the OCR_KADMOS one (<https://www.irfanview.info/plugins/kadmos/>?
Well, whichever one I'm using (The Tesseract one, according to what you
I tried the OCR_KADMOS one (in old 4.60 IrfanView 32-bit), but that>> did not seem too work too well.
Hmm! Well, as I say below, it _seems_ that OCR.DLL on my system is 1.13I have now updated to version 4.72 and am installing 'Tesseract', but
that seems a bit overwhelming (which components (not) to install?
"Space required 255.4MB"! (isn't IrfanView supposed to be
lean-and-mean?), etc.)
There are different meanings of space required. One is the space onMy Program Files (x86)\IrfanView directory is 50.5 megabytes, of which
the disk which for Tesseract is 83.4 MB. I believe that the 255 MB is > the approximation of the maximum space that the program will need as it
converts the image to the text.
the 83.4 MB is the space used on my installation of irfanview version
4.72 64 MG
On 2025/10/15 15:51:3, knuttle wrote:
On 10/15/2025 10:33 AM, Frank Slootweg wrote:
J. P. Gilliver <G6JPG@255soft.uk> wrote:
[...]
Recently I've used IrfanView's OCR function (under F9) to OCR
screenshots (and anything else - even record labels from YouTube!); it >>> seems to work pretty well (certainly fine on screenshots), and of course >>> _isn't_ online.
(I think it's a plugin, but I always download the plugins whenever I get >>> a new version of IrfanView - they're on th same page,
https://www.irfanview.com/ [bottom of home page].)
Thanks for that tip. Can you check (Help -> Installed Plugins...)
*which* plugin you use, the OCR.Dll one ('OCR using Tesseract OCR') or
the OCR_KADMOS one (<https://www.irfanview.info/plugins/kadmos/>?
I've never used that function before! It lists a lot of plugins, about
half of which are ticked. Of the two you mention, only OCR.DLL is listed
at all (and it is of course ticked).
I tried the OCR_KADMOS one (in old 4.60 IrfanView 32-bit), but that
did not seem too work too well.
Well, whichever one I'm using (The Tesseract one, according to what you
say above) works well enough for me since I realised it was there*, but
I've not thrown anything too taxing at it - mainly screenshots (which
it's more or less perfect at, as it should be!) and record labels (which
it has also done fine apart from a few extra spaces, provided I cropped
well enough to stop it "reading the furniture" as the Ronnies had it.>>
I have now updated to version 4.72 and am installing 'Tesseract', but >> that seems a bit overwhelming (which components (not) to install?
"Space required 255.4MB"! (isn't IrfanView supposed to be
lean-and-mean?), etc.)
Hmm! Well, as I say below, it _seems_ that OCR.DLL on my system is 1.13
MB.
There are different meanings of space required. One is the space on
the disk which for Tesseract is 83.4 MB. I believe that the 255 MB is
the approximation of the maximum space that the program will need as it converts the image to the text.
the 83.4 MB is the space used on my installation of irfanview version
4.72 64 MG
My Program Files (x86)\IrfanView directory is 50.5 megabytes, of which
47.7 is the Plugins one; within that, the two largest are CADImage.dll
(6.38) and Ecw.dll (5.79). Ocr.dll is 1.13. (Figures using Steffen
Gerlach's "scanner", from http://www.steffengerlach.de/freeware/ .
Despite its age, works fine - and fairly fast - in W10. [Windirstat is better, but _far_ slower.])
J. P. Gilliver <G6JPG@255soft.uk> wrote:[]
Interesting. I seem to have downloaded IV 4.72 installer - and matchingHmm! Well, as I say below, it _seems_ that OCR.DLL on my system is 1.13
MB.
No, I mean when installing, the *Tesseract* software says it needs
255.4MB.
The IrfanView Plugins page says:
"OCR - (version 4.67.4): adds OCR features to IrfanView PlugIn, requires Tesseract OCR from: https://github.com/UB-Mannheim/tesseract/wiki"
And indeed without that software, IrfanView's 'Start OCR...(Plugin)' function complains about Tesseract being absent. ("OCR engine not set
(use Settings button)" and the Settings button says "Tesseract not
found!" (it says it's looking for Tesseract.exe).)
Can you see in (Control Panel -> Programs ->) 'Programs and Features'> if you have the Tesseract software and if so what the 'Size' column
says?
[...]So if size has anything to do with it, it's no wonder the OCR works
There are different meanings of space required. One is the space on
the disk which for Tesseract is 83.4 MB. I believe that the 255 MB is
the approximation of the maximum space that the program will need as it >>> converts the image to the text.
See, here Keith (Nuttle) mentions Tesseract, so he has it. But do you> (John) have it?
the 83.4 MB is the space used on my installation of irfanview version
4.72 64 MG
My Program Files (x86)\IrfanView directory is 50.5 megabytes, of which>> 47.7 is the Plugins one; within that, the two largest are CADImage.dll>> (6.38) and Ecw.dll (5.79). Ocr.dll is 1.13. (Figures using Steffen
Gerlach's "scanner", from http://www.steffengerlach.de/freeware/ .
Despite its age, works fine - and fairly fast - in W10. [Windirstat is>> better, but _far_ slower.])
Yes, my (32-bit) IrfanView and Plugins also use about 50.5MB.
But I'm concerned about / interested in, the need for Tesseract and
*its* (installed) size.
On 2025/10/15 19:32:3, Frank Slootweg wrote:[...]
Can you see in (Control Panel -> Programs ->) 'Programs and Features'
if you have the Tesseract software and if so what the 'Size' column
says?
Interesting. I seem to have downloaded IV 4.72 installer - and matching plugin installer - 2025-5-15. Putting Tesseract into Everything, I see I downloaded tesseract-ocr-w32-setup-v5.3.0.20221214.exe 2025-7-14
(probably when I first tried to use it and got the message you
describe), and that's 51,122 KB. I also see I have tesseract.exe (dated 2022-12-14), size 1,245 KB, but I don't know what's with it ... yes, the Tesseract-OCR directory is 908 MB! 608 of that is a subdirectory called tessdata; of _that_, 329 is a sub called script, of which the largest
part by far is a file called Latin.traineddata (85.2).
Checking in the way you describe, I find "Tesseract-OCR - open source
OCR engine", apparently installed 2025/7/14, but the size column is
blank for that line. (The version is as in the name of the setup file,
and it says the Publisher is Tesseract-OCR community.)>
So if size has anything to do with it, it's no wonder the OCR works
well! (But I don't believe in that mapping.)
Thanks! Wow! Nearly a gigabyte! That's a whole other story, also
backup wise.
I think I'll first try Paul's OCR with Snipping Tool (Windows 11
only?) method or/and try the 'old' OCR_KADMOS method, before trying the
huge Tesseract thing.
Sorry, I just re-read my post and agree that wasn't clear. I meant, IChecking in the way you describe, I find "Tesseract-OCR - open source
OCR engine", apparently installed 2025/7/14, but the size column is
blank for that line. (The version is as in the name of the setup file,
and it says the Publisher is Tesseract-OCR community.)>
[...]
So if size has anything to do with it, it's no wonder the OCR works
well! (But I don't believe in that mapping.)
What do you mean by "(But I don't believe in that mapping.)"? Which 'mapping?
Thanks again for your help.
J. P. Gilliver <G6JPG@255soft.uk> wrote:
On 2025/10/15 19:32:3, Frank Slootweg wrote:[...]
Can you see in (Control Panel -> Programs ->) 'Programs and Features' >>> if you have the Tesseract software and if so what the 'Size' column
says?
Interesting. I seem to have downloaded IV 4.72 installer - and matching
plugin installer - 2025-5-15. Putting Tesseract into Everything, I see I
downloaded tesseract-ocr-w32-setup-v5.3.0.20221214.exe 2025-7-14
(probably when I first tried to use it and got the message you
describe), and that's 51,122 KB. I also see I have tesseract.exe (dated
2022-12-14), size 1,245 KB, but I don't know what's with it ... yes, the
Tesseract-OCR directory is 908 MB! 608 of that is a subdirectory called
tessdata; of _that_, 329 is a sub called script, of which the largest
part by far is a file called Latin.traineddata (85.2).
Thanks! Wow! Nearly a gigabyte! That's a whole other story, also
backup wise.
I think I'll first try Paul's OCR with Snipping Tool (Windows 11
only?) method or/and try the 'old' OCR_KADMOS method, before trying the
huge Tesseract thing.
Checking in the way you describe, I find "Tesseract-OCR - open source
OCR engine", apparently installed 2025/7/14, but the size column is
blank for that line. (The version is as in the name of the setup file,
and it says the Publisher is Tesseract-OCR community.)>
[...]
So if size has anything to do with it, it's no wonder the OCR works
well! (But I don't believe in that mapping.)
What do you mean by "(But I don't believe in that mapping.)"? Which 'mapping?
Thanks again for your help.
On 10/15/2025 3:19 PM, Frank Slootweg wrote:KN: my version of Tesseract-OCR is 5.5.0.20241111
J. P. Gilliver <G6JPG@255soft.uk> wrote:
On 2025/10/15 19:32:3, Frank Slootweg wrote:[...]
-a-a Can you see in (Control Panel -> Programs ->) 'Programs and
Features'
if you have the Tesseract software and if so what the 'Size' column
says?
Interesting. I seem to have downloaded IV 4.72 installer - and matching
plugin installer - 2025-5-15. Putting Tesseract into Everything, I see I >>> downloaded tesseract-ocr-w32-setup-v5.3.0.20221214.exe 2025-7-14
(probably when I first tried to use it and got the message you
describe), and that's 51,122 KB. I also see I have tesseract.exe (dated
2022-12-14), size 1,245 KB, but I don't know what's with it ... yes, the >>> Tesseract-OCR directory is 908 MB! 608 of that is a subdirectory called
tessdata; of _that_, 329 is a sub called script, of which the largest
part by far is a file called Latin.traineddata (85.2).
-a-a Thanks! Wow! Nearly a gigabyte! That's a whole other story, also
backup wise.
-a-a I think I'll first try Paul's OCR with Snipping Tool (Windows 11
only?) method or/and try the 'old' OCR_KADMOS method, before trying the
huge Tesseract thing.
Checking in the way you describe, I find "Tesseract-OCR - open source
OCR engine", apparently installed 2025/7/14, but the size column is
blank for that line. (The version is as in the name of the setup file,
and it says the Publisher is Tesseract-OCR community.)>
[...]
So if size has anything to do with it, it's no wonder the OCR works
well! (But I don't believe in that mapping.)
-a-a What do you mean by "(But I don't believe in that mapping.)"? Which
'mapping?
-a-a Thanks again for your help.
KN: the sizes that I quoted come from the folder properties for the
folder in C:\Program Files\Tesseract-OCR.-a I did not see any Tesseract-
OCR folders in the User\username\AppData-a folders.
What if you delete Irfanview completely.-a Remove the folders for Tesseract-OCR and Irfanview in the Program Data folder and the folder C: \Users\username\AppData\Roaming\IrfanView.
It is possible if you have update Irfanview and Tesseract-OCR several
times that some residual trash has collected in the folders.
When your computer is clean of Irfanview, restart computer and do a
complete reinstall of Irfanview, Plugins and Tesseract-OCR.
PS I did not know that Tesseract-OCR was in the main plugin file for Irfanview.-a-a I have always found it on the Plugins page on the Irfanview website and installed it from there.
Recently I've used IrfanView's OCR function (under F9) to OCR
screenshots (and anything else - even record labels from YouTube!); it
seems to work pretty well (certainly fine on screenshots), and of course _isn't_ online.
(I think it's a plugin, but I always download the plugins whenever I get
a new version of IrfanView - they're on th same page, https://www.irfanview.com/ [bottom of home page].)
On 10/15/2025 7:57 PM, knuttle wrote:KN: It is the English version
On 10/15/2025 3:19 PM, Frank Slootweg wrote:KN:-a my version of-a Tesseract-OCR-a is 5.5.0.20241111
J. P. Gilliver <G6JPG@255soft.uk> wrote:
On 2025/10/15 19:32:3, Frank Slootweg wrote:[...]
-a-a Can you see in (Control Panel -> Programs ->) 'Programs and
Features'
if you have the Tesseract software and if so what the 'Size' column
says?
Interesting. I seem to have downloaded IV 4.72 installer - and matching >>>> plugin installer - 2025-5-15. Putting Tesseract into Everything, I
see I
downloaded tesseract-ocr-w32-setup-v5.3.0.20221214.exe 2025-7-14
(probably when I first tried to use it and got the message you
describe), and that's 51,122 KB. I also see I have tesseract.exe (dated >>>> 2022-12-14), size 1,245 KB, but I don't know what's with it ... yes,
the
Tesseract-OCR directory is 908 MB! 608 of that is a subdirectory called >>>> tessdata; of _that_, 329 is a sub called script, of which the largest
part by far is a file called Latin.traineddata (85.2).
-a-a Thanks! Wow! Nearly a gigabyte! That's a whole other story, also
backup wise.
-a-a I think I'll first try Paul's OCR with Snipping Tool (Windows 11
only?) method or/and try the 'old' OCR_KADMOS method, before trying the
huge Tesseract thing.
Checking in the way you describe, I find "Tesseract-OCR - open source
OCR engine", apparently installed 2025/7/14, but the size column is
blank for that line. (The version is as in the name of the setup file, >>>> and it says the Publisher is Tesseract-OCR community.)>
[...]
So if size has anything to do with it, it's no wonder the OCR works
well! (But I don't believe in that mapping.)
-a-a What do you mean by "(But I don't believe in that mapping.)"? Which >>> 'mapping?
-a-a Thanks again for your help.
KN: the sizes that I quoted come from the folder properties for the
folder in C:\Program Files\Tesseract-OCR.-a I did not see any
Tesseract- OCR folders in the User\username\AppData-a folders.
What if you delete Irfanview completely.-a Remove the folders for
Tesseract-OCR and Irfanview in the Program Data folder and the folder
C: \Users\username\AppData\Roaming\IrfanView.
It is possible if you have update Irfanview and Tesseract-OCR several
times that some residual trash has collected in the folders.
When your computer is clean of Irfanview, restart computer and do a
complete reinstall of Irfanview, Plugins and Tesseract-OCR.
PS I did not know that Tesseract-OCR was in the main plugin file for
Irfanview.-a-a I have always found it on the Plugins page on the
Irfanview website and installed it from there.
J. P. Gilliver <G6JPG@255soft.uk> wrote:
...
Recently I've used IrfanView's OCR function (under F9) to OCR
screenshots (and anything else - even record labels from YouTube!); it
seems to work pretty well (certainly fine on screenshots), and of course
_isn't_ online.
(I think it's a plugin, but I always download the plugins whenever I get
a new version of IrfanView - they're on th same page,
https://www.irfanview.com/ [bottom of home page].)
I didn't know about this IrfanView feature plugin. So I installed https://github.com/tesseract-ocr/tesseract/releases/download/5.5.0/tesseract-ocr-w64-setup-5.5.0.20241111.exe
from https://github.com/UB-Mannheim/tesseract/wiki, and tried a screen
shot of https://github.com/UB-Mannheim/tesseract/wiki web page. However,
I get:
"? ? ? 0 ? ? ?? ganudmmmsensu????enesse?s ? ? ?? ? ?? ? ? ? ? ?? ?? ? ?
??????????????? ??? a ?????????????? ??????? ??? ?????? ???? ????????? ???? ?? ???? ?s? ?en ?? pp
?
? o m ?
? sman ???? ?????? ???s psgs ??? ?? ?? 2cm? ?? ???????
?
???s?ract at ??????? ??nnh??m ?? ?????
rmd ? pagen
me ?a??h?rm unensny many pus ??????h?s?? usss ???s???? ??? psenm ??????? rengnmen
rocn ? ????? chmuer rengnmen ?? mmenn seenn ranspapers ??g??r?? ??? ???????
preussschs sraasreneng oenscen ??sch???sgs??? me ???????? resuns enh ??????? nen men ?e??e?? ?? us ??????
????? moooo passs ??? mmens ??????? ?e??e?? m????????
???mdens
??sserad 5nstaner ??? ?????d????s ?e??e?? mendssor
msuen pnms
renenny ?? ??? ??s?ra? ??? ??????? snu ?????? ??? mere ????? anm me ??? ? a ??s??ens ????????
enssen ????s ?????? ?? hen ???n s ??ss??? snmner ?? menens ???
menene ????sa ???????? ?? ?????? ???????? sn me ?sr?s???y ???????? ss sussemd ????????
me snmensm ?? sn ? ??? ?????????? ??? ?????????????? remens en ?????????? srsmenan ?? ??????????????
??????????? ? ???? snmnea ???????sa sn ?? ???ss??? ???????? enn dsrenry ?? ?? reenend ? ?????? ??? ??????? ???????????
enh ?? ?? sumremrses ?? ????
me ????? snmners ??? ?? ?en??????? hen
? p ?????
? ??ess?racpccr??????4?s??up?5?5???2024? ? ??s?e ????? ???
? ? p ?? ?
men ?? ansu ???? ?s??ss??s ? ?2 and sa ?? ??s?den? ???a??? renc ?? ????
m addmen ?? ansu pensds dommemauen ???????? ens gensmed ?y ?????g??g??? ? ?????????? ????????
??sserad modds ??r h5stor5c ???nTs cen ?? ??? ??????
? nnp????gae??????cen??????? ?
? ?rs???? ??????? prsmed sn rmenr ?????? ??? suppensd ?? ?? ??????? mudens ??????
??????? ??? ????? ??p?rm??r?? ? ??????? ?? ?????? en enn ???d?ns ??? a ?????? rsnge ?
? ???????? ????????? mey ??? ????????????? ?????? ? many ??? ms resuns ???m ???? menms
o rorrnnnppsoooooo? ???????? ???????????? ??? ?????? ????? ????? nen me ???????? ?????????
? ? ? ?????g? sn ? ??? g??? ? ??? ????????? ? ??????? ????? ???? ???????? ?"
Um, it can't even OCR at all from the clear web page screen shot. Am I missing something? :( I do have Tesseract options' primary language for osd.traineddata. Does that have English?
-+ FAQ (deutsch)
On Wed, 10/15/2025 8:02 PM, Ant wrote:
J. P. Gilliver <G6JPG@255soft.uk> wrote:
...
Recently I've used IrfanView's OCR function (under F9) to OCR
screenshots (and anything else - even record labels from YouTube!); it
seems to work pretty well (certainly fine on screenshots), and of course >>> _isn't_ online.
(I think it's a plugin, but I always download the plugins whenever I get >>> a new version of IrfanView - they're on th same page,
https://www.irfanview.com/ [bottom of home page].)
I didn't know about this IrfanView feature plugin. So I installed
https://github.com/tesseract-ocr/tesseract/releases/download/5.5.0/tesseract-ocr-w64-setup-5.5.0.20241111.exe
from https://github.com/UB-Mannheim/tesseract/wiki, and tried a screen
shot of https://github.com/UB-Mannheim/tesseract/wiki web page. However,
I get:
Big snip <
The easy way is to download this Nirsoft viewer: https://www.nirsoft.net/utils/windows_updates_history_viewer.html
It needs no install, shows everything including failed updates, and will generate a HTML report of all or selected entries.
On Thu, 10/16/2025 3:08 AM, Paul wrote:
On Wed, 10/15/2025 8:02 PM, Ant wrote:
J. P. Gilliver <G6JPG@255soft.uk> wrote:
...
Recently I've used IrfanView's OCR function (under F9) to OCR
screenshots (and anything else - even record labels from YouTube!); it >>>> seems to work pretty well (certainly fine on screenshots), and of course >>>> _isn't_ online.
(I think it's a plugin, but I always download the plugins whenever I get >>>> a new version of IrfanView - they're on th same page,
https://www.irfanview.com/ [bottom of home page].)
I didn't know about this IrfanView feature plugin. So I installed
https://github.com/tesseract-ocr/tesseract/releases/download/5.5.0/tesseract-ocr-w64-setup-5.5.0.20241111.exe
from https://github.com/UB-Mannheim/tesseract/wiki, and tried a screen
shot of https://github.com/UB-Mannheim/tesseract/wiki web page. However, >>> I get:
Command line usage is described here,
so you can tune what you're attempting.
https://tesseract-ocr.github.io/tessdoc/Command-Line-Usage.html
On 10/15/2025 8:01 PM, knuttle wrote:
On 10/15/2025 7:57 PM, knuttle wrote:
What if you delete Irfanview completely.-a Remove the folders for
Tesseract-OCR and Irfanview in the Program Data folder and the folder
C: \Users\username\AppData\Roaming\IrfanView.
It is possible if you have update Irfanview and Tesseract-OCR several
times that some residual trash has collected in the folders.
When your computer is clean of Irfanview, restart computer and do a
complete reinstall of Irfanview, Plugins and Tesseract-OCR.
PS I did not know that Tesseract-OCR was in the main plugin file for
Irfanview.-a-a I have always found it on the Plugins page on the
Irfanview website and installed it from there.
Interesting. As I - AFAIK! - only have it as an IV plugin, I have noKN:-a my version of-a Tesseract-OCR-a is 5.5.0.20241111KN: It is the English version
- only have it as an IVSetting, Apps, installed Apps.
{kind=link}
{kind=link}